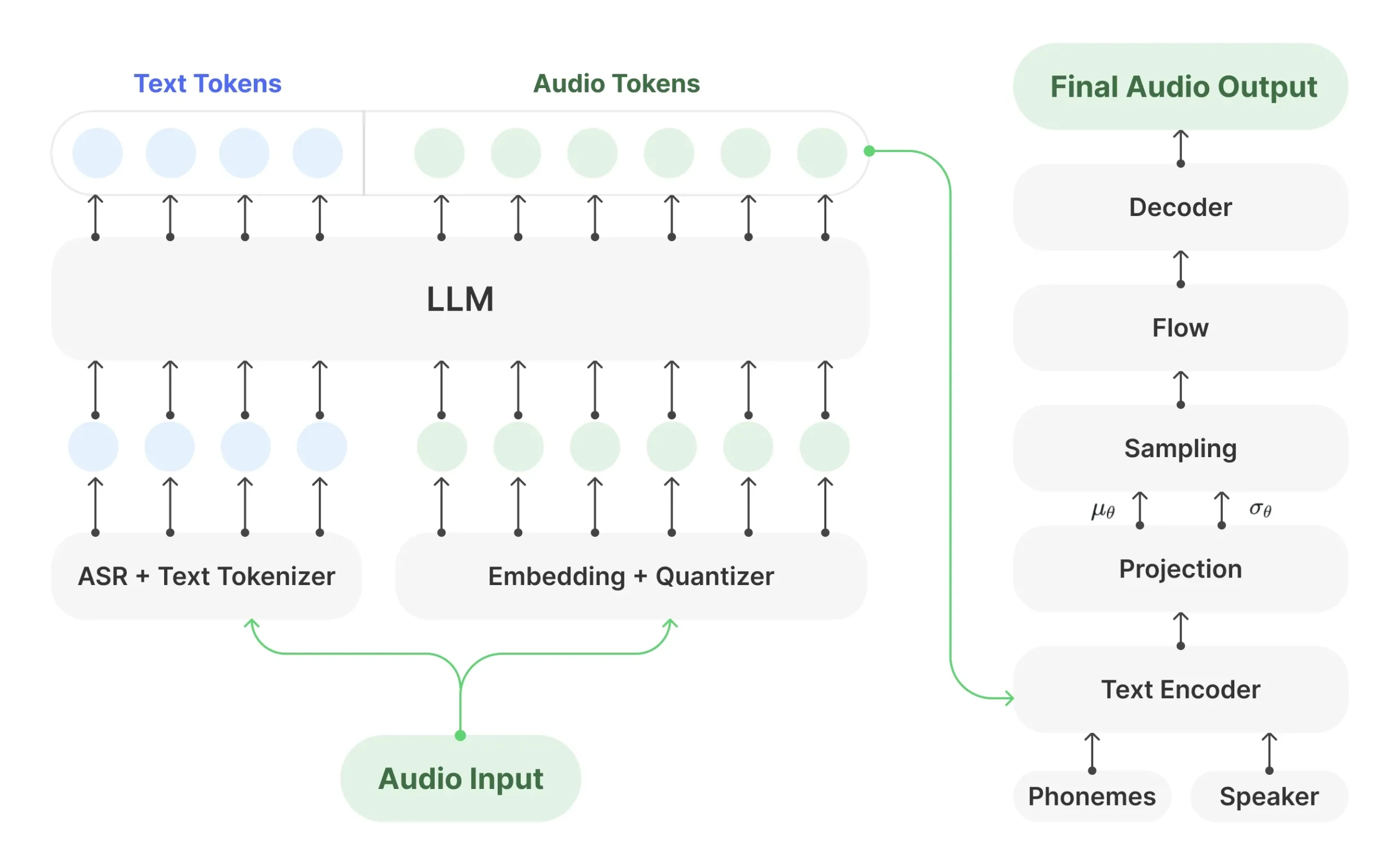
Orpheus-TTS
综合介绍
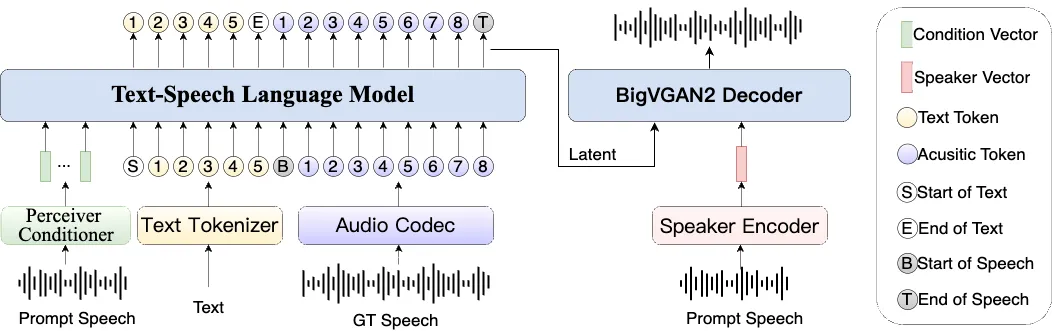
Orpheus-TTS 是一个由 Canopy AI 开发的开源文本转语音(TTS)项目。 它基于 Llama-3b 大型语言模型构建,旨在生成听起来像人类的自然语音。 该模型通过在新增加的音频词元上进行训练,使其能够直接生成语音波形,展现了大型语言模型在语音合成领域的潜力。Orpheus-TTS 的核心能力包括生成带有自然语调和情感的语音,无需事先训练即可克隆声音(零样本语音克隆),并能通过特定标签(如 <laugh> 或 <sigh>) 控制输出语音的情绪。 该项目支持低延迟的实时语音流生成,并提供了预训练和微调好的多种模型,包括专门针对日常应用的英语模型和一套多语言模型。 作为一个开源项目,开发者可以自由访问和修改其源代码,以适应特定的研究或应用需求。
功能列表
- 类人语音合成:能够生成带有自然节奏、停顿和情感的语音,效果优于部分闭源模型。
- 零样本语音克隆:无需事先对特定声音进行微调,即可克隆任何语音。
- 情感和语调控制:用户可以通过在文本中添加简单的标签(如
<laugh>,<chuckle>,<sigh>,<cough>等)来引导模型生成带有特定情感的语音。 - 低延迟流式生成:支持实时音频流输出,延迟约为200毫秒,并可通过输入流优化至100毫KOM]左右,适合实时应用场景。
- 多语言支持:除了提供两个精调的英语模型外,还发布了一系列多语言模型,支持包括中文、西班牙语、法语、德语等多种语言。
- 开源和可定制:项目代码以 Apache-2.0 许可证开源,允许开发者自由进行修改、微调和二次开发。
- 多种模型提供:提供了一个在超过10万小时英语数据上训练的预训练基础模型,以及一个为日常TTS应用优化过的微调产品模型。
- 音频水印:支持使用 Silent Cipher 技术为生成的音频添加水印,以追踪音频来源。
使用帮助
Orpheus-TTS 提供了多种使用方式,从业余爱好者到专业开发者都可以找到适合自己的方法。以下是详细的使用和安装说明。
环境要求
- Python 3.8 或更高版本。
- 推荐使用带有 GPU 的环境以获得最佳性能,特别是对于模型微调和实时推理。
一、快速上手:使用 pip 命令安装
这是最简单直接的使用方式,适合想要快速体验模型功能的用户。
- 克隆项目仓库首先,从 GitHub 克隆 Orpheus-TTS 的官方仓库,其中包含了最新的代码和示例。
git clone https://github.com/canopyai/Orpheus-TTS.git - 安装核心依赖进入项目目录,并通过
pip安装orpheus-speech包。这个包内包含了运行模型所需的核心组件,它底层利用vllm库进行快速推理。cd Orpheus-TTS pip install orpheus-speech注意:根据官方文档,
vllm在2025年3月18日的一个版本存在一些小问题,如果遇到bug,可以尝试在安装orpheus-speech后,回退vllm的版本:pip install vllm==0.7.3。 - 编写并运行Python脚本创建一个Python文件(例如
test_orpheus.py),并写入以下代码。这段代码将加载微调过的产品模型,并根据输入的文本生成一段语音,最后保存为output.wav文件。from orpheus_tts import OrpheusModel import wave import time # 加载模型,这里使用的是为日常应用微调过的产品模型 model = OrpheusModel(model_name="canopylabs/orpheus-tts-0.1-finetune-prod", max_model_len=2048) # 准备需要转换的文本,可以加入一些自然的停顿词和情感 prompt = '''天呐,社交媒体彻底改变了我们的互动方式,这太疯狂了,对吧?就像,我们现在全天候在线,但不知怎的,人们却感觉比以往任何时候都更孤独。更别提它对孩子们的自尊心和心理健康造成的影响了。''' # 记录开始时间 start_time = time.monotonic() # 生成语音流 syn_tokens = model.generate_speech( prompt=prompt, voice="tara", # 选择一个预设的声音,如 tara, leah, leo 等 ) # 将音频流数据写入 WAV 文件 with wave.open("output.wav", "wb") as wf: wf.setnchannels(1) # 单声道 wf.setsampwidth(2) # 采样宽度为2字节 (16-bit) wf.setframerate(24000) # 采样率为 24000 Hz total_frames = 0 # 逐块处理音频数据流,实现流式写入 for audio_chunk in syn_tokens: frame_count = len(audio_chunk) // (wf.getsampwidth() * wf.getnchannels()) total_frames += frame_count wf.writeframes(audio_chunk) # 计算并打印生成耗时和音频时长 duration = total_frames / wf.getframerate() end_time = time.monotonic() print(f"用时 {end_time - start_time:.2f} 秒,生成了 {duration:.2f} 秒的音频。") - 执行脚本在终端中运行该脚本,执行完毕后,你会在当前目录下找到一个名为
output.wav的音频文件。python test_orpheus.py
二、模型微调
对于有特定需求(如特定声音、风格或语言)的用户,Orpheus-TTS 支持在其基础上进行微调。
- 准备数据集数据集需要是 Hugging Face
datasets格式。每一条数据包含文本和对应的音频。官方提供了一个 数据预处理的Colab笔记 来帮助你转换数据格式。高质量的结果通常在50个样本后开始显现,但为了达到最佳效果,建议每个说话者提供约300个样本。 - 安装微调所需依赖
pip install transformers datasets wandb trl flash_attn torch ``` 同时,你需要登录 Hugging Face 和 wandb 以便上传模型和记录训练过程。 ```bash huggingface-cli login wandb login - 配置和运行训练
- 修改
finetune/config.yaml文件,将你的数据集地址和训练参数填入。 - 使用
accelerate启动训练脚本train.py。
accelerate launch train.py - 修改
三、使用社区提供的工具
社区也为 Orpheus-TTS 贡献了一些便捷的工具,让不熟悉代码的用户也能轻松使用。
- Gradio WebUI:一个在本地运行的图形用户界面,操作简单直观。
- LM Studio 客户端:一个轻量级的客户端,可以使用 LM Studio API 在本地运行 Orpheus-TTS。
- HuggingFace Space:社区成员搭建的在线体验空间,无需本地安装即可试用。
应用场景
- 实时语音助手和虚拟人Orpheus-TTS 的低延迟特性使其非常适合用于需要实时语音反馈的应用,如智能客服、语音助手或数字虚拟人的对话系统,能够提供更自然、流畅的交互体验。
- 有声读物和内容创作该模型能够生成带情感的、富有表现力的语音,非常适合将长篇文字内容(如新闻、博客、小说)转换为高质量的有声读物,为内容创作者提供高效的音频制作工具。
- 个性化音频和品牌声音通过零样本语音克隆或模型微调,企业可以为自己的品牌创建一个独特的声音,并应用于广告、产品介绍和客户服务中,从而增强品牌形象的一致性。
- 游戏开发和角色配音游戏开发者可以利用 Orpheus-TTS 为游戏中的非玩家角色(NPC)快速生成大量对话语音,甚至可以根据游戏情境动态生成带有特定情感的台词,极大地丰富了游戏世界的沉浸感。
QA
- Orpheus-TTS 和其他TTS模型有什么不同?Orpheus-TTS 的主要区别在于它基于一个大型语言模型(Llama-3b)构建。 这使得它不仅能理解文本的字面意思,还能在一定程度上理解其语义和上下文,从而生成更符合人类表达习惯的语调和情感。此外,它是一个完全开源的项目,为研究和定制提供了极大的灵活性。
- 我没有强大的GPU,可以在本地运行Orpheus-TTS吗?可以。虽然GPU能提供最佳性能,但项目也提供了在没有GPU的环境下使用 Llama.cpp 进行推理的实现文档。 这意味着即使在普通的CPU上也能运行,只是速度会慢一些。对于普通用户,也可以使用社区提供的在线HuggingFace Space进行体验,无需本地安装。
- 什么是零样本语音克隆?效果如何?零样本语音克隆指的是模型仅通过一小段目标语音的样本,就能模仿这个声音的音色、韵律和风格,而不需要经过长时间的训练或微调。 Orpheus-TTS 的预训练模型支持此功能,你提供的语音样本越丰富,克隆出的声音就越逼真。
- 使用这个模型进行语音克隆是否存在法律或道德风险?是的。语音克隆技术如果被滥用,可能涉及身份盗用、诈骗和隐私侵犯等严重问题。 因此,在使用此功能时,必须遵守相关的法律法规,并遵循道德准则,例如,必须获得声音所有者的明确同意,并对生成内容的使用负责。